- Published on
mysql 高级知识4
- Authors

- Name
- ArJun
- @Twitter/NibabaAJ
- Name
MySQL高级知识-第1章
[toc]
说明
这里使用 MariaDB 作为数据库 MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护
安装过程
windows 平台直接下载msi格式 最新稳定版本是10.4
备注:windows安装完成需要重新
Fedora 平台 -----默认测试环境
1.使用root用户执行下面的命令进行安装:
dnf install mariadb-server mariadb-client
2.服务开启,使用root用户执行
systemctl start mariadb #启动服务
systemctl enable mariadb #设置开机启动
systemctl restart mariadb #重新启动
systemctl stop mariadb.service #停止MariaDB
3.为 MariaDB 配置远程访问权限
select User, host from mysql.user;
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
FLUSH PRIVILEGES;
逻辑架构
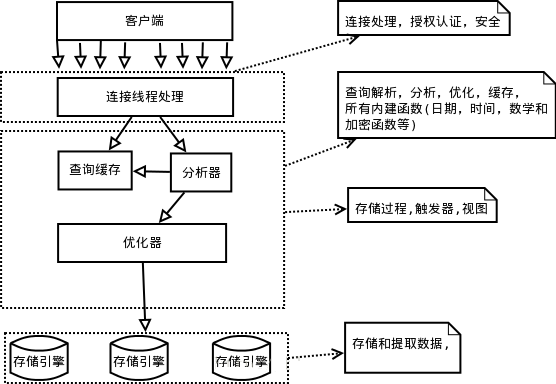
架构详细描述:
MySQL逻辑架构整体分为三层,最上层为客户端层,并非MySQL所独有,诸如:连接处理、授权认证、安全等功能均在这一层处理。
MySQL大多数核心服务均在中间这一层,包括查询解析、分析、优化、缓存、内置函数(比如:时间、数学、加密等函数)。
所有的跨存储引擎的功能也在这一层实现:存储过程、触发器、视图等。最下层为存储引擎,其负责MySQL中的数据存储和提取。
和Linux下的文件系统类似,每种存储引擎都有其优势和劣势。-默认都是InnoDB
中间的服务层通过API与存储引擎通信,这些API接口屏蔽了不同存储引擎间的差异。
每一个客户端发起一个新的请求都由服务器端的连接/线程处理工具负责接收客户端的请求并开辟一个新的内存空间,在服务器端的内存中生成一个新的线程,当每一个用户连接到服务器端的时候就会在进程地址空间里生成一个新的线程用于响应客户端请求,用户发起的查询请求都在线程空间内运行, 结果也在这里面缓存并返回给服务器端。线程的重用和销毁都是由连接/线程处理管理器实现的。
综上所述:
用户发起请求,连接/线程处理器开辟内存空间,开始提供查询的机制。
查询过程
用户总是希望MySQL能够获得更高的查询性能,最好的办法是弄清楚MySQL是如何优化和执行查询的。
一旦理解了这一点,就会发现:很多的查询优化工作实际上就是遵循一些原则让MySQL的优化器能够按照预想的合理方式运行而已。
当向MySQL发送一个请求的时候,MySQL到底做了些什么呢?
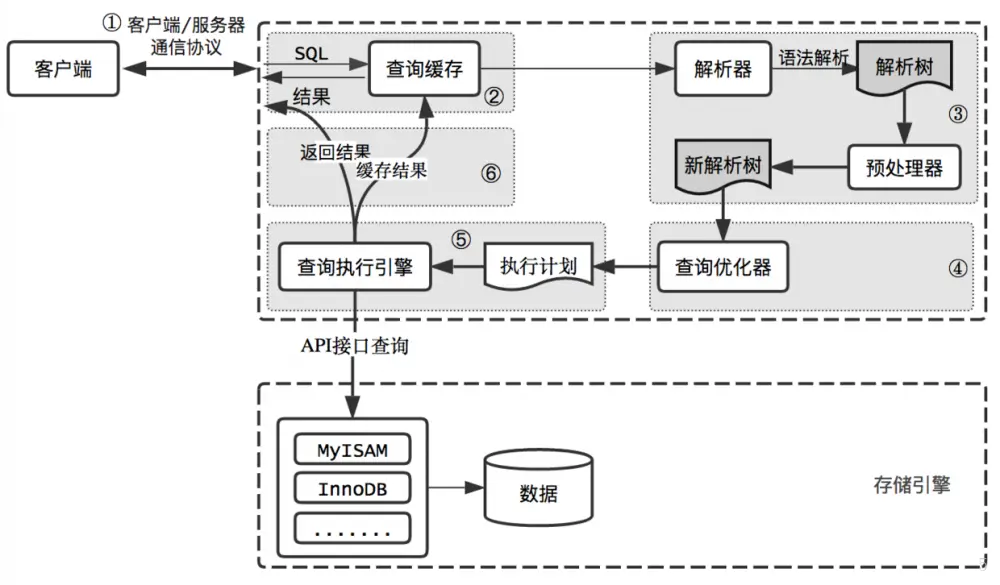
查询缓存
简单的说就是MySQL会优先检查这个查询是否命中查询缓存中的数据,可以使用下面命令查看:
SHOW VARIABLES LIKE 'query_cache%'
运行结果:
"query_cache_limit" "1048576"
"query_cache_min_res_unit" "4096"
"query_cache_size" "1048576"
"query_cache_strip_comments" "OFF"
"query_cache_type" "OFF"
"query_cache_wlock_invalidate" "OFF"
这些参数介绍:
query_cache_limit: MySQL能够缓存的最大结果,如果超出,则增加 Qcache_not_cached的值,并删除查询结果
query_cache_min_res_unit: 分配内存块时的最小单位大小
query_cache_size: 缓存使用的总内存空间大小,单位是字节,这个值必须是1024的整数倍,否则MySQL实际分配可能跟这个数值不同(感觉这个应该跟文件系统的blcok大小有关)
query_cache_type: 是否打开缓存 OFF: 关闭 ON: 总是打开
query_cache_wlock_invalidate: 如果某个数据表被锁住,是否仍然从缓存中返回数据,默认是OFF,表示仍然可以返回
语法解析器和预处理器
1.语法解析器
MySQL通过关键字将SQL语句进行解析,并生成一棵对应的“解析树”
2.预处理器
根据一些MySQL规则进一步检查解析树是否合法,例如,这里讲检查数据表和数据列是否存在,还会解析名字和别名
查询优化器
优化器的作用就是找到最好的执行计划
查询执行引擎
在解析和优化阶段,MySQL将生成查询对应的执行计划,MySQL的查询执行引擎则根据这个执行计划来完成整个查询。
这里执行计划是一个数据结构,而不是和很多其他的关系型数据库那样会生成对应的字节码。
相对于查询优化阶段,查询执行阶段不是那么复杂:MySQL只是简单的根据执行计划给出的指令逐步执行。
在根据执行计划逐步执行的过程中,有大量的操作需要通过调用存储引擎实现的接口来完成
返回结果给客户端
查询执行的最后一个阶段是将结果返回给客户端。
即使查询不需要返回结果给客户端,MySQL仍然会返回这个查询的一些信息,如查询影响到的行数。
基本命令
新建数据库
1.默认create database db_name命令,生成的数据库是latin1编码
MariaDB [(none)]> create database test;
Query OK, 1 row affected (0.001 sec)
查看所有数据库情况:
MariaDB [test]> SELECT SCHEMA_NAME 'database', default_character_set_name 'charset', DEFAULT_COLLATION_NAME 'collation' FROM information_schema.SCHEMATA;
+--------------------+---------+-------------------+
| database | charset | collation |
+--------------------+---------+-------------------+
| information_schema | utf8 | utf8_general_ci |
| test | latin1 | latin1_swedish_ci |
| mysql | latin1 | latin1_swedish_ci |
| performance_schema | utf8 | utf8_general_ci |
+--------------------+---------+-------------------+
4 rows in set (0.001 sec)
查看单个数据库:
MariaDB [(none)]> use test;
Database changed
MariaDB [test]> show variables like "collation_database";
+--------------------+-------------------+
| Variable_name | Value |
+--------------------+-------------------+
| collation_database | latin1_swedish_ci |
+--------------------+-------------------+
1 row in set (0.001 sec)
MariaDB [test]> show variables like "character_set_database";
+------------------------+--------+
| Variable_name | Value |
+------------------------+--------+
| character_set_database | latin1 |
+------------------------+--------+
1 row in set (0.001 sec)
如果想要生成utf8mb4编码,可以使用下面命令
create database test default character set utf8mb4 collate utf8mb4_unicode_ci;